01 août 2023 By Christian Blaise
One of our loyal historical clients asked us if we could improve his proofing process.
Indeed, it processes a lot of files in its control and proofing workflow and, in many cases, the files contain technical inks such as die-cut, varnish, etc. These inks are obviously using spot colors and, therefore, when the proofs are printed, it is, therefore, necessary to also measure these inks in the control strips in order to ensure the compliance of the documents, whereas this is not necessary (because they are only technical inks).
Of course, one would tell us that there is in virtually every RIPs on the market, a feature that allows to manage an exception table in order to ignore these inks. Indeed, this is the case, but this operation requires knowing beforehand the name of the inks in the document and add them to the table before sending the file to the RIP so that it can be ignored.
These exception tables must also be managed for each RIP used.
This is not very efficient in terms of operation and is a major impairer of productivity.
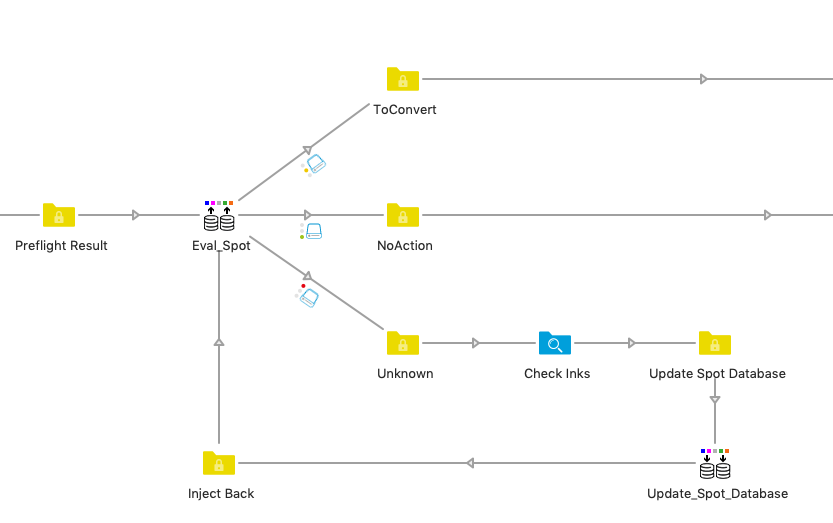
We decided to use Enfocus Switch to make machine learning before sending to the proofing systems. We’ve then developed a Switch flow that is going to analyze the file to determine which spot colors are present in the document and then compare each ink against two database tables, one containing the inks to keep,the other the inks to convert (and in which process separation).
The file sent to the proofing system is therefore processed by our script and the conversion or retention information is added to the metadata of the job.
But what happens when a new ink is used and is not present in either table? The file will then be sent to a Switch client,and an operator will be asked to choose for each unknown ink if it is necessary to keep or convert it (and in this case, in which way). Following the answers given by the operator, the information of each unknown ink will then be stored either in the retention table or in the conversion table – it is no longer unknown!
The file goes back to analysis, and all the inks are now known, so all conversion and retention information is written in the job’s metadata , giving the PDF processing tool the necessary instructions. Using a PDF profile containing variables, the file will be processed in accordance with the request for proofing!
The next file containing these same inks can then be processed directly by the system without the operator’s intervention. The machine now knows what to do – it has become smarter, thanks to the machine learning process!
Over time, fewer and fewer files contain unknown inks, and the operator’s intervention decreases until completely disappears… before a new file where someone has had a new idea of naming 😉
Our client confirmed that the reliability and productivity gains were immediate, and that the management of these technical inks is no longer a problem. Machine learning has succeeded in making the process intelligent 🧠
Are you also interested in this smart converter to integrate into your proofing workflow? Contact us!
Do you still have any questions? Don’t hesitate to comment below and we’ll be happy to answer your questions!
Nous utilisons des cookies pour suivre l'utilisation et les préférences. Pour en savoir plus, consultez notre page sur les cookies.